
Mastering Grep: Identifying Search Patterns with Grep & Regular Expressions Fundamentals

Ever struggled to manually search for specific text patterns in a document? Say goodbye to that challenge with our tailored solution!
Grep, short for Global Regular Expression Print, is an invaluable utility that leverages “regular expressions” to articulate intricate search patterns. These patterns are applicable to text files and code across diverse programming languages.
For those new to grep commands, the seemingly simple task of searching for a specific word might raise questions. To dispel any confusion, it’s crucial to note that while basic regular expressions excel in text files, advanced ones prove their mettle in intricate situations and programming scenarios. So, whether you’re dealing with straightforward text or diving into more complex coding, grep has you covered.
Jump To...
What does the term 'Grep Regular Expression' refer to?
A grep regular expression is a set of characters defining a distinct pattern, which is then compared against all text in a file. When the text or code in the file aligns with the user-specified pattern, it is visually highlighted for the user.
If the technical terms mentioned above have left you perplexed, let’s simplify it. This article will comprehensively explain each element of a grep regular expression.
Pattern matching using regex
Various operating systems and command line interfaces exhibit their unique variations of regular expressions. Nonetheless, in Grep, regular expressions typically consist of both literal characters and meta characters.
Literal Characters
Literal characters are special symbols representing a single character, such as ‘a’ or ‘8’. They precisely match the pattern, offering accuracy and precision. Literal characters may encompass the following symbols:
Regular character
Period character
A character string
Numerical characters
Brace characters
Meta Characters
A Meta character, conversely, is a character with a predefined meaning known to the computer program. Meta characters possess predetermined meanings in the computer interface, facilitating the creation of patterns. These meta-character patterns play a crucial role in text searching.
Regular meta characters include ‘()’ and ‘^’, while others like ‘*’ and ‘.’ have distinct predefined meanings in various operating systems.

Grep
As previously stated, Grep (Global regular expression print) is a utility utilizing regular expressions to articulate a search pattern.
In Grep, regular expressions go beyond mere literal characters or meta-characters. They encompass anchors, escape characters, and character classes.
Anchors
Anchors in a grep command specify the position where a match should occur in a text. The two main anchors with a specified location are matches at the start and at the end of a line. These anchors help to identify complex matches.
Escape Characters
An escape character refers to a backslash ‘\’ in different programming languages. This escape character is referred to as a literal character. On the other hand, the escaped pipe character is a metacharacter that performs alteration. This character is written as ‘|’.
Character Classes
These character classes usually refer to square brackets consisting of two characters ‘[ ]’. Users can insert any words to search string in a text file. This bracket expression matches the specified criteria in the files. For example, if a user inputs the following command, ‘[aeiou]’, the command will match the input to any vowel.
How would you define the grep command?
A grep command is a sequence of characters in an expression that allows the user to search for a specific pattern in input files or text streams. The grep command makes use of the BRE syntax. This basic syntax, which is used for the grep regex patterns, is given as:
grep [options] pattern [file…]

The syntax for grep searches incorporates crucial keywords within bracket expressions. The ‘options’ within the first bracket expression serve as modifiers to refine searches, while ‘file’ in the second bracket expression specifies the file to be searched.
An illustrative example of a grep regex command is:
grep -n “error” logfile.txt
In this example, the command will display lines containing errors in the log file, accompanied by line numbers. This aids users in identifying specific occurrences in the code, making it essential for locating relevant lines.
Categories of Regular Expressions
Regular expressions come in various forms, each serving different functionalities. It’s crucial to choose the appropriate type depending on the complexity involved in your desired pattern matching.
While the Basic Regular Expression (BRE) format is suitable for straightforward text patterns, it may not seamlessly handle more complex operations. Let’s delve into the various types of regular expressions:
Fundamental Regular Expressions
The Basic Regular Expression (BRE) is the most commonly used format in grep regex patterns, known for its simplicity and beginner-friendly mechanisms.
In these expressions, most meta-characters lose their original meaning unless a backslash is placed before them, like ‘$\’. If the first character of these expressions stands alone, meta-characters lose their special significance entirely.
For instance, the following command searches for a specific string in configuration files:
grep “pattern” filename
To search for a word at the beginning of a line, use the expression:
grep “^pattern” filename
Similar to the previous example, the expression below is employed to search for lines starting with a specific pattern followed by any characters:
grep “^pattern.*” filename
Another common expression for searching lines containing any one of multiple words is exemplified as:
grep “word1\|word2” filename
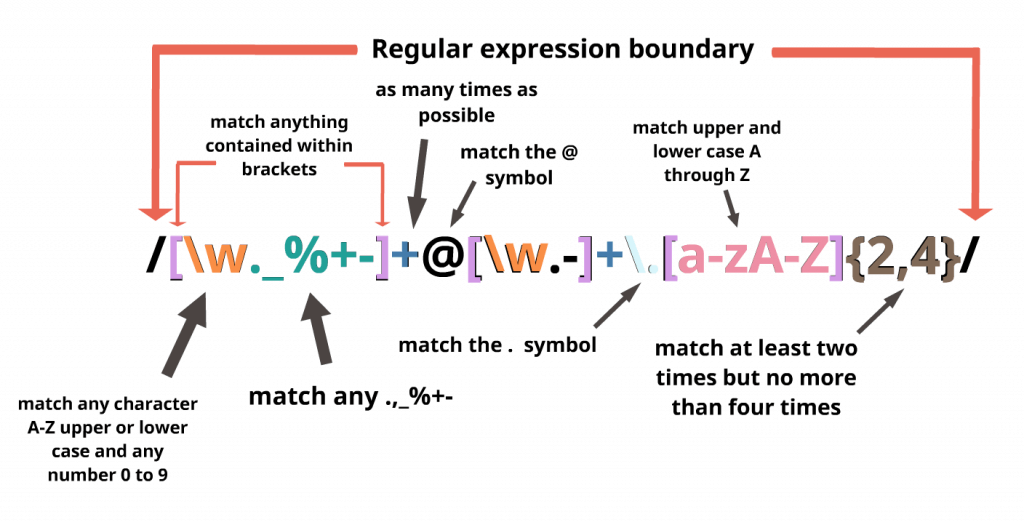
Advanced Regular Expressions
Extended Regular Expressions (ERE) build upon BRE, introducing meta-characters without requiring escape expressions. ERE also brings additional expression mechanisms beyond the basic usage of BRE. To enable the ERE option in ‘grep regex’, users can utilize the ‘-E’ option.
In ERE form, an alternative expression for searching lines containing either “word1\|word2” is presented as:
grep -E “word1\|word2” filename
The following command demonstrates how to search for lines where a character occurs zero or more times in a text file:
grep -E “char” filename
To search for lines with any single character, the following user input expression is used:
grep -E “a.b” filename
To search for lines with a pattern that has a preceding character pattern in the text, the following example is given as input:
grep -E “pattern1.*pattern2” filename
To search for lines with a specific character range of lowercase letters ‘a-z’ in a file, the following pattern is used:
grep -E “[a-z]” filename
The same output as the given command can also be replicated for uppercase letters. For uppercase letters, the two characters in the bracket should be changed from ‘a-z’ to ‘A-Z’:
grep -E “[A-Z]” filename
Regular Expressions Compatible with Perl
This type of regular expression is a highly advanced format, so it is not as commonly used for grep regex. The Perl-compatible regular expressions are designed to be used with the special characters of the Perl syntax.
These expressions in grep regex include the lookahead and lookbehind assertions. To enable the PCRE option in ‘grep regex’, users can install the ‘pcregrep’ option at the beginning of a line.
To search for lines starting with any characters that have a preceding character as “pattern”, the command is:
pcrеgrеp “word1|word2” filеnamе
Writing ‘pcregrep’ at the very beginning of a grep regex expression is the only thing that needs to be done to use its features. The command to search for lines with the occurrence of a character for zero or more times is given as:
pcrеgrеp “colou?r” filеnamе
For an exact match of all the lines with one pattern followed by another pattern, the source code is provided as:
pcrеgrеp “pattеrn1.*pattеrn2” filеnamе
Another command to determine the exact number of lines with a specific number of characters in a word is:
pcrеgrеp “\<word_lеngth\>” filеnamе
Applying a Simple Regular Expression to a File
To utilize a Basic Regular Expression (BRE) in a command line file, the syntax includes the command ‘grep’, the pattern expressing what you are looking for, and the filename indicating where you are searching:
grep “pattern” filename
Locating a Particular String
To search for a specific string in the file, assuming it is not an empty string and the file does not have any empty lines, the following command will display all the lines in the file that contain the user-provided string:
grep “you need to install pcregrep as it is” file1.txt
However, it should be noted that in most cases, the example provided will match specific words within the quotation. The only variant considered is “you need to install pcregrep as it,” and no other variations such as, “you need to install pcregrep as it” or “YOU NEED TO INSTALL PCREGREP AS IT.”
This corresponds to a case-sensitive search that you can employ in your system to find any variations of the above example.
grep -i “you need to install pcregrep as it is” file1.txt
This statement will match lines with “you need to install pcregrep as it is“, “You need to install pcregrep as it is” and “YOU NEED TO INSTALL PCREGREP AS IT IS”.
Showing Line Numbers
Through the advanced features of our Linux system, users can also search for the line number along with the matched lines. This helps users locate the specific occurrence of a pattern in a file.
grep -n “you need to install pcregrep as it is” file1.txt
Additionally, users can find the line numbers for patterns that are not included in the specified pattern.
grep -v “you need to install pcregrep as it is” file1.txt
If the pattern to match has no occurrences in the files, then the output will display empty lines.
How can you verify regular expressions in Linux?
There are multiple ways to search for special patterns or regular patterns in Linux. One way involves using the built-in echo function of Linux. This word is specified at the beginning of the expression in the command:
echo “you need to install pcregrep as it is” | grep -E “install pcregrep”
Do not worry if running the command results in “do not echo” appearing irrelevant, as you can proceed with it as normal without necessarily providing an “echo” statement in the source code. Using ‘grep’ directly with the files is done as follows:
grep -E “install pcregrep” file1.txt
Another commonly used command for implementing regex functions in Linux is using ‘regex’ itself. The above expressions will be written in the following form:
echo “you need to install pcregrep as it is” | regex “install pcregrep”
The use of the echo command may vary when employing the regex function, and while it is not always necessary, there are instances where using echo can be essential for interaction with the command line.
What characterizes an invalid regular expression?
Mastering the fundamental syntax and character sequence for crafting grep commands is crucial for beginners. An invalid regular expression typically refers to a pattern that doesn’t adhere to the specific syntax rules of the language in use. Such invalid expressions can result in syntax errors, runtime issues, or other complications.
Syntax Errors
Regular expressions generally follow a specific syntax, which varies based on the programming language in use. It’s crucial for users to adhere to this syntax when coding and providing instructions to the system.
Here are some examples of common syntax errors that programmers may encounter:
An unclosed bracket
An invalid quantifier
Misspelling of keywords
Unsupported Features
Certain features and keywords may not be present in every regular expression engine. Users cannot employ such features if there is no support. When the system detects attempts to use unsupported features, it fails to produce the expected results and instead generates an error message.
(?<=lookbehind) or (?<=status>…) are not features supported in all regex functions.
Unescaped Special Characters
Certain characters hold special or pre-defined meanings in regular expressions. When a user intends to match them literally, it’s essential to escape these characters; failure to do so might render the expression invalid.
Using an * without preceding character or escape
Conclusion
It’s crucial for beginners to grasp the fundamental command structure of this language before diving into its usage. Essentially, the main takeaway from this article is that there’s no need to delve into complex algorithms and patterns immediately. Take your time to learn the basics and progress gradually.
Mastering the skills of using grep and regular expressions is challenging but highly rewarding. We’ve provided users with the best instructions and knowledge to navigate the world of grep and regular expressions effectively.
If you can learn how to use effective expressions and arrange them correctly to find the patterns you need in a file, then you’ve gained a comprehensive understanding of grep!

